

Romper o consenso sobre o Pordata
Por Paulo Trezentos (*)
Imagine imprimir todas as páginas Web da Internet portuguesa e guardar impressas na Biblioteca Nacional para consulta pelos cidadãos. Faz sentido?
Nas próximas linhas tentarei fazer o paralelo entre o exemplo dado e o Pordata.
O Pordata é uma iniciativa lançada pela Fundação Francisco Manuel dos Santos para "tentar responder às necessidades de informação credível, tantas vezes dispersa e de acesso nem sempre simples ...".
[caption] [/caption]
[/caption]
Como todas as iniciativas, temos o "Quem?", "O quê?", "Estratégia?" e "Táctica?".
A iniciativa Pordata é inquestionável no "Quem" - uma fundação privada com trabalho feito, n' "O Quê" - disponibilizar dados estatísticos credíveis e na "Táctica" - o site é bem-feito, organizado e apelativo.
A reflexão que trago é apenas sobre a "Estratégia" seguida, sendo que essa reflexão não pretende colocar em causa a qualidade, mérito e empenho dos envolvidos. Pelo contrário, a pequena contribuição é um reconhecimento da importância que a disponibilização de estatísticas pode ter.
A estratégia seguida pelo Pordata foi fazer uma recolha sistemática de dados pelas instituições que os detêm e estruturá-los de forma a serem facilmente acessíveis para consulta ou exportação.
Os dados estão dentro dos servidores do Pordata e não nas instituições de origem o que tem as suas vantagens mas muitas desvantagens.
Em particular, a estratégia teria sido melhor conseguida se o Pordata fosse um agregador de fontes com ligações para as instituições originais, sendo esta ligação feita via Webservices ou ligações a ficheiros remotos.
Este agregador tem muito espaço para desenvolver trabalho: pode institucionalmente sensibilizar a organização de origem para disponibilizar os dados de forma estruturada em Webservices ou pode do seu lado ter mecanismos de transformação de dados para ficarem da forma mais útil ao utilizador. Mesmo sem os dados fisicamente guardados, o utilizador continuaria a aceder ao Pordata para usufruir da agregação e serviços de transformação.
Este tipo de agregador de fontes, chamemos-lhe OpenData para simplificação de designação, tem como exemplo o site DataGov mantido pelo governo americano em que é seguida esta lógica.
A seguinte tabela resume as diferenças entre a abordagem OpenData e o Pordata:
[caption]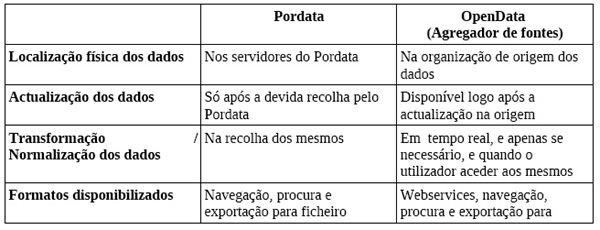 [/caption]
[/caption]
O agregador de fontes, como referido na linha "Formatos disponibilizados", deve assentar na ligação a Webservices fornecidos pela organização de origem.
Webservices são formas estruturadas de disponibilizar os dados que permitem que aplicações de terceiros acedam e os utilizem para diferentes fins como "data visualization" ou integração com outros dados para criação de valor.
A disponibilização de WebServices é a base essencial para que os dados possam ter uma utilização total e intensiva. É a partir desta tendência que se sucedem na Internet os chamados "mashups".
Numa época em que os dados são actualizados muitas vezes diariamente, não faz sentido a recolha e armazenamento centralizado da informação.
Porém, a agregação de fontes é necessária para democratizar o acesso aos dados e a sua utilização. Esta função está ainda por cumprir, seja pelo melhoramento do Pordata seja pelo surgimento de outra iniciativa.
(*) Paulo Trezentos, director técnico do Caixa Mágica e investigador do ISCTE
Comentários