

Começou por se chamar Tumba!, ainda como projeto académico em 2001 por um grupo da Faculdade de Ciências da Universidade de Lisboa, depois mudou para Tomba e só em 2007 assumiu oficialmente o nome de Arquivo.pt, evoluindo para um serviço público em 2012. Na verdade, a designação é provavelmente o que menos interessa, num projeto pioneiro que pretende guardar a memória da Internet em Portugal e que já soma 17 anos ao serviço da comunidade, com provas dadas em desenvolvimento de tecnologia e inovação.
“Somos uns felizardos porque o Estado dá acesso livremente a todo este arquivo de informação”, defende Daniel Gomes, que é fundador do projeto e desenvolveu o arquivo digital da Internet em Portugal na FCCN, que integra a Fundação para a Ciência e a Tecnologia (FCT). Em entrevista ao SAPO TEK não consegue esconder o orgulho com o serviço que foi construído e que está disponível de forma gratuita para todos os que o quiserem usar.
No arquivo há 30 anos de sites guardados, com a memória de páginas que já não existem mas que fazem parte da narrativa e evolução da Internet em Portugal e que contribuem para enriquecer a história. No acervo está, por exemplo, a primeira página da Internet publicada em Portugal.

O Memorial do Arquivo.pt, que preserva sites antigos, e o projeto Renascer, que recupera sites históricos cujo conteúdo deixou de estar disponível online, são alguns dos exemplos de iniciativas desenvolvidas que usam a base de informação recolhida e a tornam útil.
Os números que suportam a plataforma são impressionantes, com mais de 20 mil milhões de ficheiros da web arquivados, 50 milhões de websites e 1,4 PetaByte em formato comprimido. E o Arquivo.pt continua a crescer todos os dias.
Daniel Gomes admite que nem todas as pessoas têm consciência do valor deste arquivo mas lembra que as Sociedades sem memória são um risco para a civilização. “Já ninguém lê informação em papel, todos os documentos que circulam são digitais e é importante preservá-los”, sublinha.
Em Portugal o Arquivo.pt assumiu este trabalho de preservação das páginas de Internet, mas existem outros projetos a nível internacional que seguem esta missão. O Internet Archive é um dos mais conhecidos, mas há outros bons exemplos, como o Web Recorder, para além de serviços de empresas privadas, que são pagos.
O projeto tem sido reconhecido e o Arquivo.pt coleciona muitas distinções, como o Prémio Transformação Digital 2024 ou o Melhor Projeto Digital da Administração Pública Central, mas promove também os seus próprios prémios, destacando trabalhos inovadores realizados com base na informação histórica preservada pelo Arquivo.pt.
A edição de 2025 está em curso e as candidaturas podem ser entregues até 6 de maio, sendo que na lista dos premiados em edições anteriores estão os trabalhos “Noticioso – Desafiar percepções” e o “discordAR: a Proximidade dos Partidos na Assembleia da República”, entre outros que podem ser conhecidos no site da iniciativa.
Um arquivo ao serviço da investigação
Daniel Gomes diz que o arquivo é cada vez mais utilizado, por cidadãos anónimos e por investigadores, mas o gestor do projeto tem uma meta. “O objetivo é que todas as pessoas saibam o que é o Arquivo.pt. Só se o conhecerem é que o podem utilizar”, admite.
Procurar uma determinada página, uma narrativa ou uma imagem são tarefas que se tornam fáceis no site Arquivo.pt. mas vale a pena navegar também nas Exposições online e visitar as coleções para descobrir temas como as memórias do 25 de abril na internet, ou a evolução da Rádio Comercial ao longo de 40 anos e a viagem no tempo com o Jornal Público.

Para além das memórias, o Arquivo.pt é também um repositório de grande valor que pode ser usado em projetos de investigação, nas áreas de pesquisa e de análise de informação, por exemplo, mas mais recentemente também para o treino de Large Language Models (LLM), como aconteceu com o GlórIA.
“Apesar da abundância de LLMs para muitas línguas de recursos elevados, a disponibilidade de tais modelos continua a ser limitada para o português europeu”, explicam os autores do GlórIA, Ricardo Lopes, João Magalhães, David Semedo, investigadores da Faculdade de Ciência e Tecnologia da Universidade Nova de Lisboa, no seu artigo GlórIA – A Generative and Open Large Language Model for Portuguese. O modelo utilizou 35 000 milhões de tokens, ou expressões que as máquinas conseguem processar, de diversas fontes.
Agora a ideia é usar também o Arquivo.pt para treinar o AMÁLIA, o novo LLM para português que integra a Estratégia Digital Nacional e a Agenda Nacional de Inteligência Artificial, como adiantou a ministra da Juventude e Modernização em entrevista ao SAPO TEK. A versão beta deve ser apresentada ainda no primeiro trimestre de 2025, segundo o calendário que foi partilhado.
Informação em risco de desaparecer
Quanto mais informação coleciona, e mais antiguidade dos dados consegue manter, mais valioso é o serviço do Arquivo.pt, como salienta o responsável do projeto. Ao contrário do que parece ser senso comum, nem tudo o que está na Internet é para sempre, e todos os dias são eliminadas grandes quantidades de dados de sites.
Dados de estudos do Pew Research Center indicam que 38% das páginas web deixam de estar acessíveis depois de uma década, mas o número depende muito do tipo de informação. Um estudo feito por Daniel Gomes, durante o seu doutoramento, indica cerca de 50% dos endereços disponíveis a uma determinada data se tornam indisponíveis passados apenas 2 meses, e que 80% dos conteúdos são alterados ou desaparecem passado um ano. Em alguns casos, os sites mudam várias vezes ao dia, como acontece com as páginas dos jornais online.
“Há muita volatilidade e estes arquivos preservam a memória digital”, destaca o fundador do projeto, contrapondo com a maior duração da preservação da informação em papel.
A volatilidade traz associada o risco de que o acesso ao conhecimento se quebre e por isso o Arquivo.pt assume a responsabilidade de fazer com que a informação publicada online permaneça acessível para as gerações futuras.
Aliar investigação ao arquivo
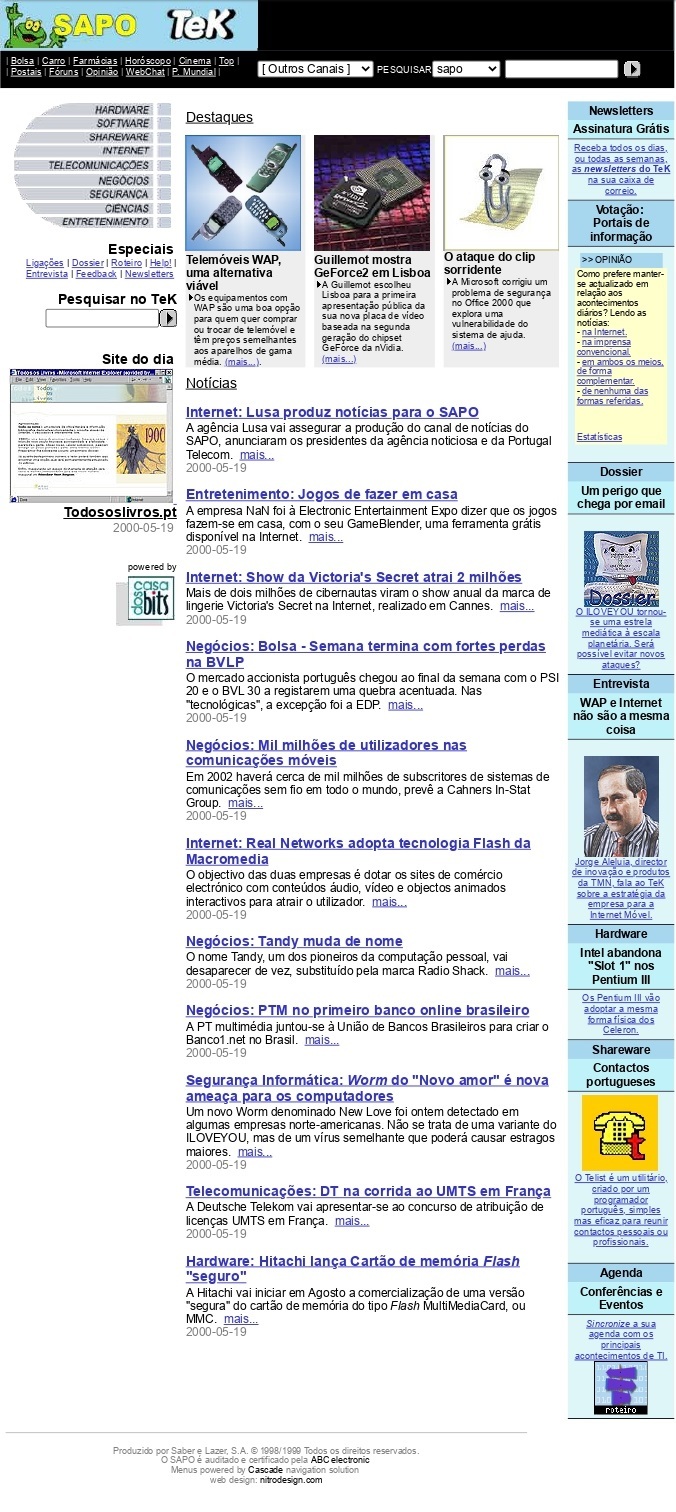
Viajar no tempo, regressando a páginas arquivadas desde 1996, é uma das possibilidades para quem queira conhecer a evolução dos sites atuais ou recordar alguns projetos que já não existem. Ainda se lembra como era o SAPO TEK quando foi lançado em fevereiro de 2000? As memórias estão guardadas e à distância de uma pesquisa e alguns cliques.








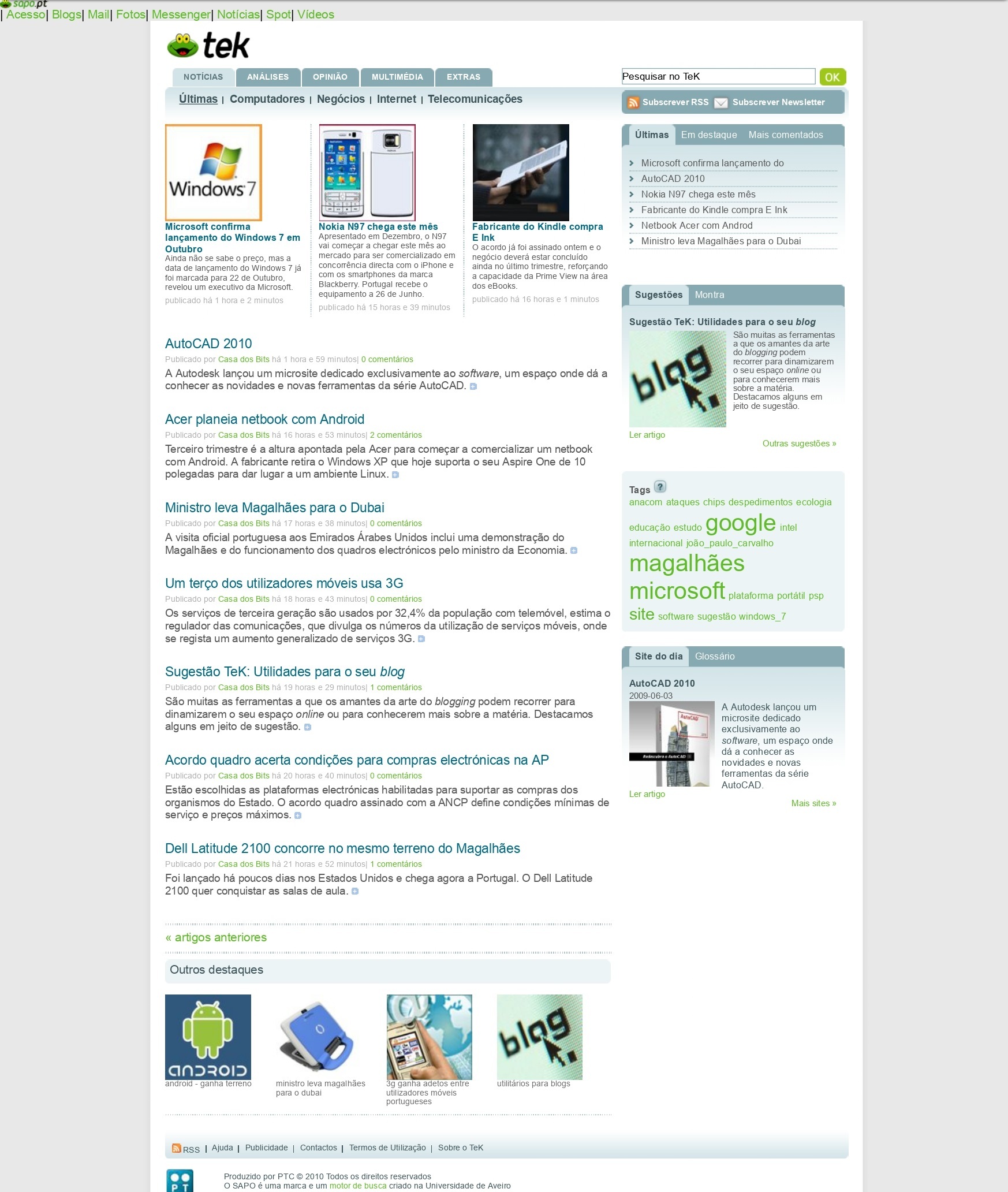
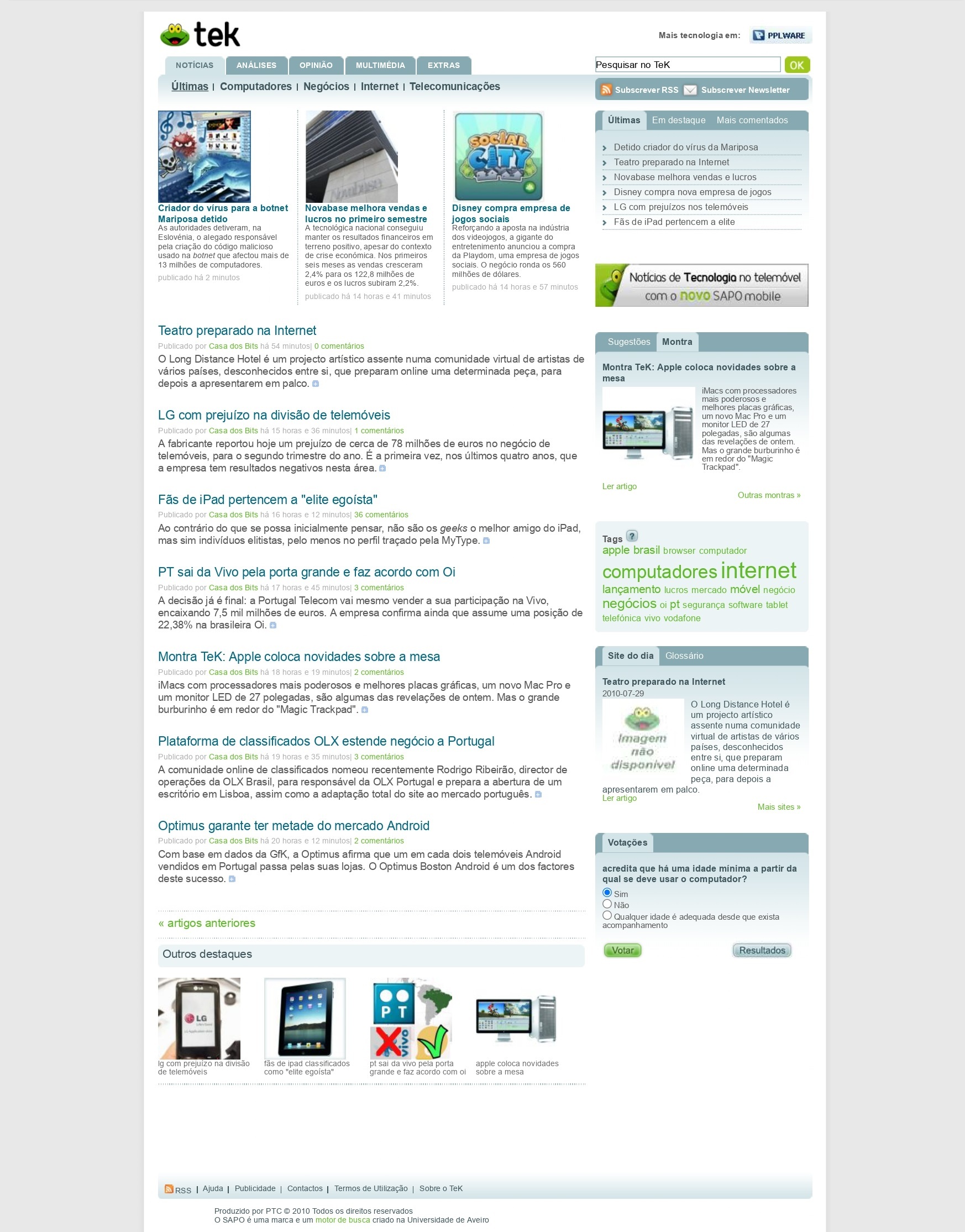
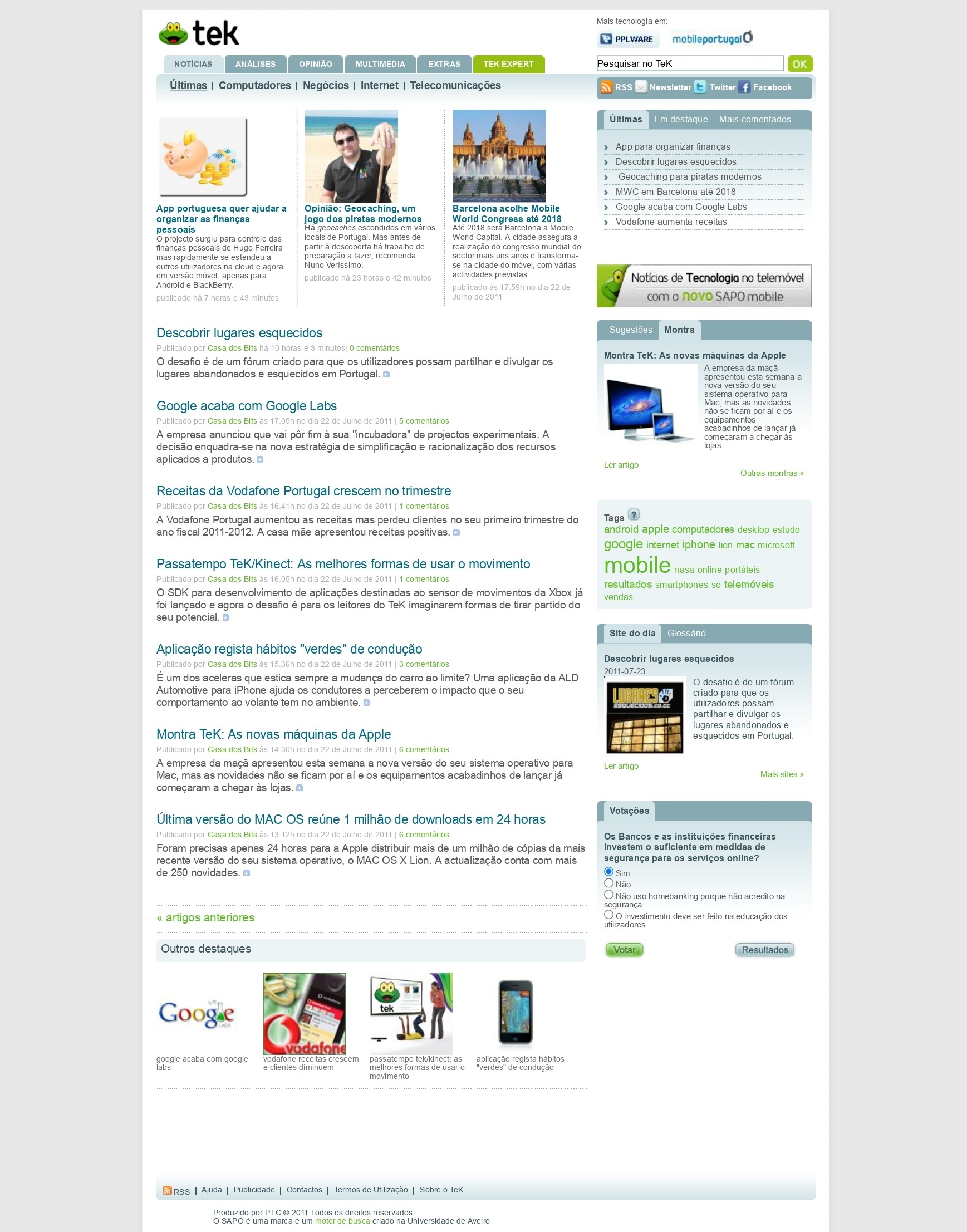




Nos servidores da FCCN está guardada a informação, que é cuidadosamente preservada e gerida pela equipa do Arquivo.pt, que também desenvolve investigação sobre a preservação de dados digitais. Nos últimos anos disponibilizou já 13 serviços, sendo alguns públicos e outros direcionados a entidades parceiros, entre os quais se contam o CitationSave e o Arquivo404.
A equipa desenvolve a tecnologia que permite suportar os serviços e o acervo do Arquivo.pt numa área de investigação onde não há muito desenvolvimento, porque quase toda a tecnologia que é desenvolvida foi pensada para aceder aos dados mais recentes. Por isso a tecnologia tem de ser adaptada para processar dados históricos da Web. O desafio passa pela sustentabilidade do repositório mas também pela tecnologia de indexação e preservação, já que cada página pode ter várias versões arquivadas ao longo do tempo. Isso significa que não pode ser identificada por um mesmo URL, tem de ser identificada por outros dados, como data de publicação e arquivo.
“Quando há um problema não podemos contratar serviços, temos de ser nós a investigar e desenvolver”, afirma Daniel Gomes, reconhecendo o mérito da equipa que tem solucionado alguns problemas mais complexos de arquivo, e que beneficia das plataformas partilhadas com a FCCN. “Podemos estar orgulhosos porque temos o arquivo da Web com os métodos de pesquisa e acesso mais avançados do mundo”, garante.
Para já “o nosso sistema tem acompanhado o crescimento do volume de informação de forma graciosa” e por vezes é necessário adicionar máquinas, substituir discos e fazer evoluir a arquitetura, assumindo o fundador que "é sempre o nosso desafio".
Ainda assim, há alguma incerteza, porque a plataforma está assente em centenas de milhares de linhas de código, também baseado em outros projetos semelhantes a nível internacional, como o Internet Archive e o Web Recorder, que são referências nesta área.
“Há um ou dois anos o sistema colapsou com um bug do sistema que recolhia determinados endereços no índice estavam a ser recolhidos milhões de vezes”, explica Daniel Gomes. Com a investigação descobriu-se o problema e esse trabalho levou a alterações no sistema.
A tecnologia de Inteligência Artificial tem sido usada pelo Arquivo.pt para melhorar o sistema de pesquisa e os modelos de aprendizagem automática foram mesmo o tema de uma tese de doutoramento de Miguel Costa, um dos membros da equipa.
O Arquivo.pt suporta pesquisa de texto, de imagem e métodos de pesquisa avançada para cada um deles, integra com outros serviços como o Conta-me Histórias que gera narrativas sobre qualquer assunto, com tecnologia desenvolvida por investigadores portugueses, e também tem pesquisa em bloco para investigadores.
Uma API desenvolvida na última década facilita o acesso aos dados e é possível extrair informação de texto, imagens ou PDFs, mas também viajar nas coleções disponibilizadas, selecionando a partir dai a informação que quer usar. “Estamos sempre disponíveis para colaborar nos projetos”, sublinha Daniel Gomes, e no acervo do site podem encontrar-se vários exemplos dessas colaborações.
Veja também
Em destaque
-
Multimédia
IRON é (mesmo) um robot humanoide ou um humano disfarçado? Xpeng tira a limpo as dúvidas -
Site do dia
Faça a edição de ficheiros PDF gratuitamente online no website Sedja -
App do dia
North War: Island Defense 3D desafia à construção de um exército e recuperar o reino perdido -
How to TEK
Organize as suas reuniões e videochamadas através do agendamento no WhatsApp
Comentários